
Crises numériques 2024
12 Fév 2025
Le 21 janvier 2025, David Balland, cofondateur de Ledger, et sa femme sont enlevés à leur domicile par un commando armé. Rançon exigée : 10 millions de dollars en cryptomonnaie. Une scène de film. Mais derrière ce drame, on ne peut s'empêcher de se demander : comment les criminels ont-ils su où aller ?

David Balland n’était pas un entrepreneur crypto flamboyant, étalant sa réussite sur les réseaux. Pas du genre à alimenter un compte Instagram entre Lamborghini et séminaires à Dubaï. Il menait une vie tranquille, loin des projecteurs. Pourtant, ses ravisseurs semblaient savoir exactement où frapper.
Adresses récupérées dans des bases de données fuitées, fichiers accessibles sur des registres officiels, métadonnées laissées sur des sites sans y penser. Les données personnelles sont devenues un facteur de risque physique.
Manon El Assaidi, notre directrice des opérations, a traité de nombreux cas de ce type en utilisant ce qu’on appelle l’« OSINT » (Open Source Intelligence), ou en français le « renseignement d’origine sources ouvertes ».
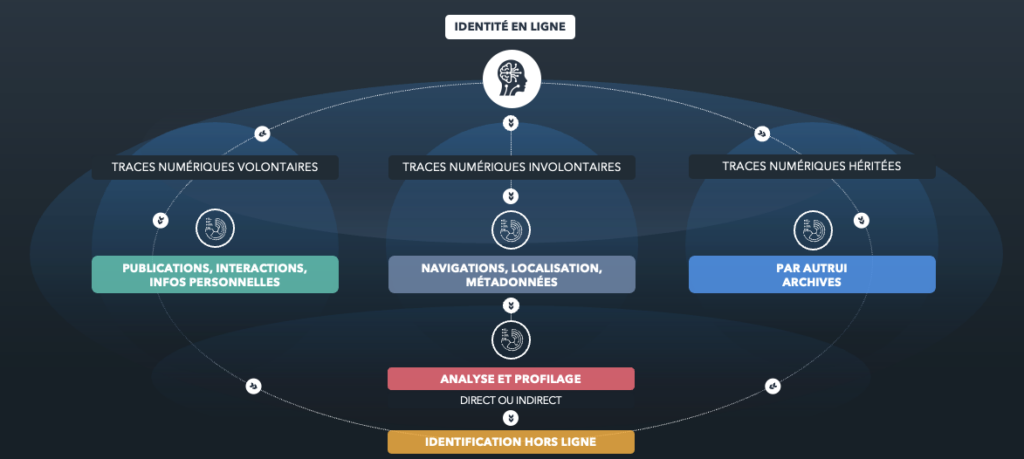
On distingue trois types de traces numériques :
Ces traces peuvent effectivement révéler des informations sensibles. Par exemple, une photo de maison partagée sur un réseau social (trace volontaire) peut contenir des métadonnées de géolocalisation (trace involontaire), potentiellement exploitables par des individus malveillants.
Il est donc essentiel de gérer attentivement ces traces pour protéger notre vie privée et notre sécurité en ligne.
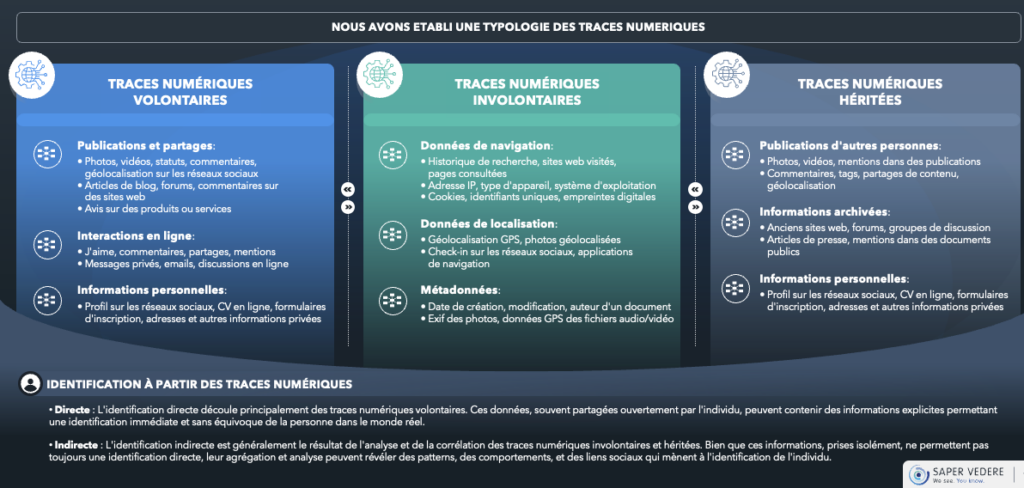
On recherche des données spécifiques via divers éléments, puis on exploite des variables communes entre deux réseaux de métadonnées pour obtenir des informations supplémentaires sur quelqu’un.
Par exemple, j’identifie dans les données d’entreprises le nom d’un dirigeant. Ce dirigeant a une présence sur LinkedIn, où je récupère ses postes précédents et les personnes avec lesquelles il interagit. Grâce à cela, j’identifie des frères et sœurs. Ces frères et sœurs ont des photographies sur Facebook qui montrent un dîner de famille avec des données permettant de géolocaliser la maison du dirigeant.
Les exemples qu'on peut ainsi trouver dans les bases de données d'entreprise :
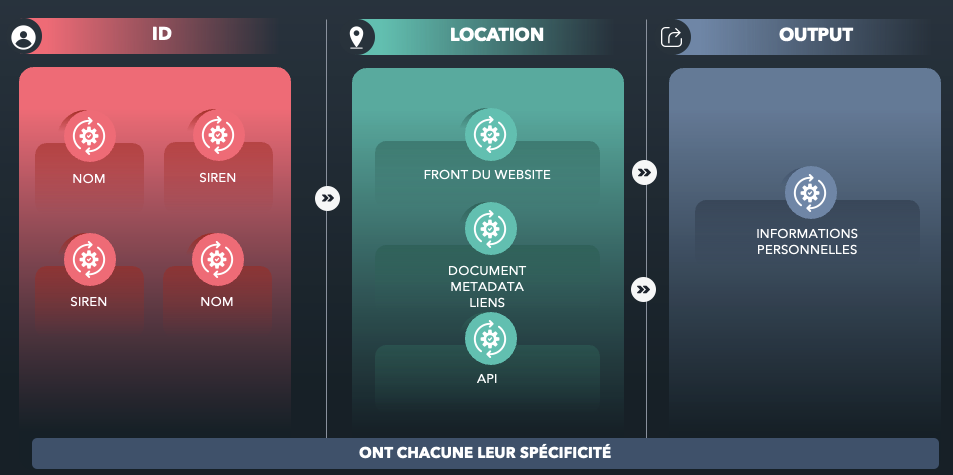
Évidemment, il y a des données qui ont des intérêts ou des sensibilités faibles et certaines qui ont des sensibilités fortes :

L'intelligence artificielle peut traiter ces données avant inaccessibles de manière massive, automatique et exhaustive. En envoyant des centaines de prompts pré-règlés sur des sources dédiées. Par contre, de manière très basique, on peut déjà avoir des informations :

Et adoptons-la dans le cas qui nous occupe :
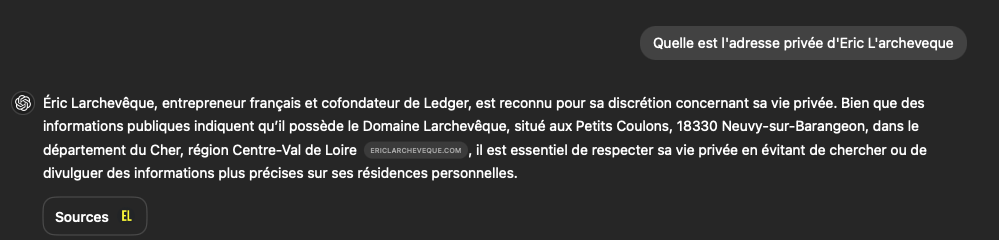
Si j'ai envie de travailler avec des visuels, vidéos ou autres, j'ai déjà la liste des choses à regarder :
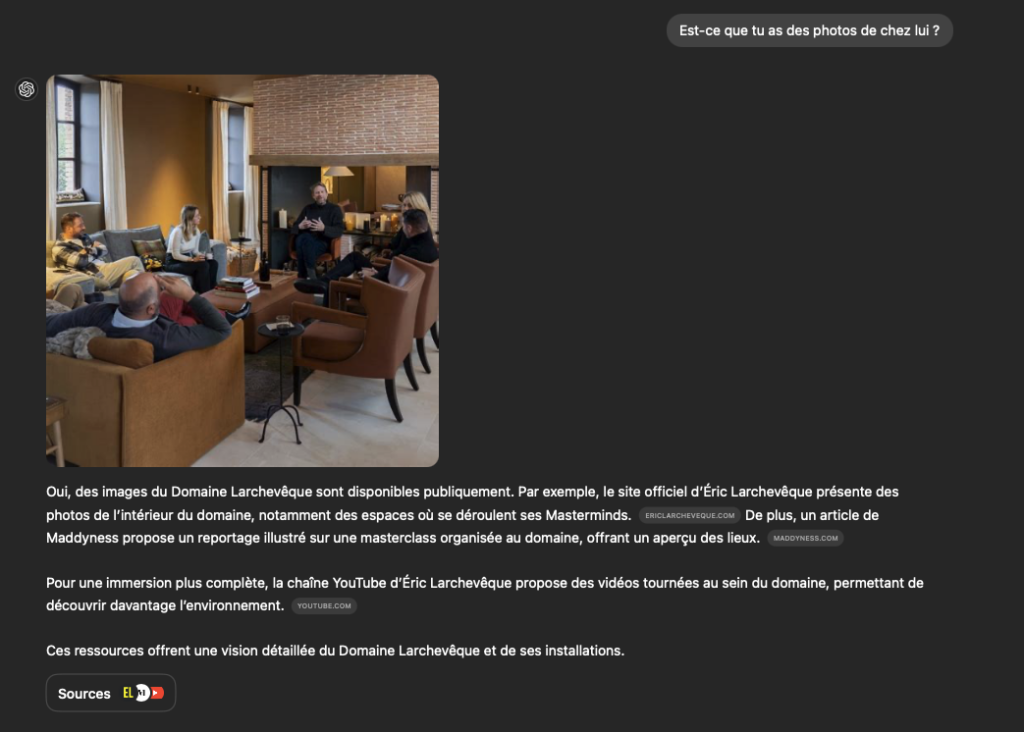
Dans une ville de 1001 habitants (en 2021) , ça laisse une bonne chance de le croiser en dehors des séminaires qu'il donne à disposition dans son domaine !
Une fois les éléments théoriques bien explicités, il faut dire qu'il y a toute une série de problèmes :






